二叉树定义:
概念: 节点的度:节点所拥有子树的个数称为节点的度 叶子节点:度为0的节点成为叶子节点,或称为终端节点 祖先节点:从根节点到该节点所经分支上的所有节点 双亲节点:树中某节点有孩子节点,则这个节点称为它孩子节点的双亲节点,双亲节点也成为前驱节点 兄弟节点:具有相同双亲节点的节点称为兄弟节点 树的度:树中所有节点的度的最大值成为该树的度 节点的层次:从根节点到树中某节点所经路径上的分支也称为该节点的层次,根节点的层次为1,其他节点层次是双亲节点层次加1 树的深度:树中所有节点的层次的最大值称为该树的深度 分支结点:度不为零的结点 性质: 1.二叉树第 i 层上节点数目最多为 2i-1 2.深度为 k 的二叉树,最多有 2k-1 个节点 3.包含 N 个节点的二叉树,高度至少为 log2(N+1) 4.任意一颗二叉树中,终端节点(叶子)有 n0 个,度为2的节点有 n1个,则 n0=n1+1(叶子节点=双分支节点+1)
1.满二叉树
定义:高度为 h,并且由 2h–1 个结点的二叉树,被称为满二叉树
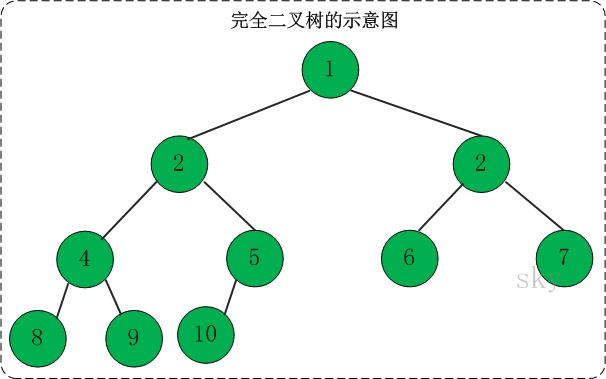
2.完全二叉树
定义:二叉树中,每一层的节点都是从左向右连续排列,除最后一层该二叉树是满二叉树
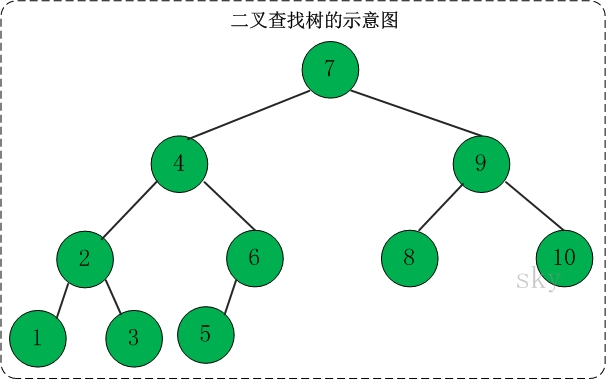
3.二叉查找树(二叉搜索树,Binary Search Tree)
定义:左边的节点小于中间节点,右边的节点大于中间节点
4.平衡二叉树(Balanced Binary Tree)
平衡二叉树(Balanced Binary Tree)又被称为AVL树(有别于AVL算法),且具有以下性质: 它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用算法有红黑树、AVL树等。 在平衡二叉搜索树中,我们可以看到,其高度一般都良好地维持在O(log2n),大大降低了操作的时间复杂度。 最小二叉平衡树的节点的公式如下: F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量
5.平衡查找树之 AVL树
AVL树定义:AVL树是最先发明的自平衡二叉查找树。AVL树得名于它的发明者 G.M. Adelson-Velsky 和 E.M. Landis, 他们在 1962 年的论文 “An algorithm for the organization of information” 中发表了它。 在AVL中任何节点的两个儿子子树的高度最大差别为1,所以它也被称为高度平衡树,n个结点的AVL树最大深度约1.44log2n。查找、插入和删除在平均和最坏情况下都是O(logn)。 增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。 这个方案很好的解决了二叉查找树退化成链表的问题,把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间, 不过相对二叉查找树来说,时间上稳定了很多。AVL树的自平衡操作——旋转:AVL树最关键的也是最难的一步操作就是旋转。旋转主要是为了实现AVL树在实施了插入和删除操作以后,树重新回到平衡的方法
6.平衡二叉树之 红黑树
红黑树的定义:红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它是在1972年由鲁道夫·贝尔发明的,称之为”对称二叉B树”, 它现代的名字是在 Leo J. Guibas 和 Robert Sedgewick 于1978年写的一篇论文中获得的。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的: 它可以在O(logn)时间内做查找,插入和删除,这里的n是树中元素的数目。红黑树和AVL树一样都对插入时间、删除时间和查找时间提供了最好可能的最坏情况担保。这不只是使它们在时间敏感的应用如实时应用(real time application)中有价值, 而且使它们有在提供最坏情况担保的其他数据结构中作为建造板块的价值;例如,在计算几何中使用的很多数据结构都可以基于红黑树。此外,红黑树还是2-3-4树的一种等同,它们的思想是一样的 ,只不过红黑树是2-3-4树用二叉树的形式表示的。 红黑树的性质: 性质1. 节点是红色或黑色。 性质2. 根是黑色。 性质3. 所有叶子都是黑色(叶子是NIL节点)。 性质4. 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。) 性质5. 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
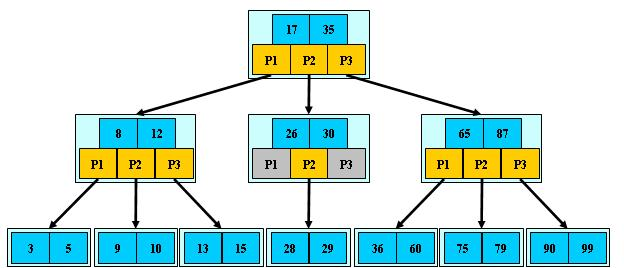
7.B 树
B树也是一种用于查找的平衡树,但是它不是二叉树。
B树的定义:B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
在B树中查找给定关键字的方法是,首先把根结点取来,在根结点所包含的关键字K1,…,Kn查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查找的关键字在Ki与Ki+1之间,Pi为指向子树根节点的指针,此时取指针Pi所指的结点继续查找,直至找到,或指针Pi为空时查找失败。
B树作为一种多路搜索树(并不是二叉的):
1) 定义任意非叶子结点最多只有M个儿子;且M>2;
2) 根结点的儿子数为[2, M];
3) 除根结点以外的非叶子结点的儿子数为[M/2, M];
4) 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5) 非叶子结点的关键字个数=指向儿子的指针个数-1;
6) 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7) 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8) 所有叶子结点位于同一层;
如下图为一个M=3的B树示例:
8.B+ 树
B+树是B树的变体,也是一种多路搜索树:1) 其定义基本与B-树相同,除了:2) 非叶子结点的子树指针与关键字个数相同;3) 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);4) 为所有叶子结点增加一个链指针;5) 所有关键字都在叶子结点出现;
B+树的搜索与B树也基本相同,区别是B+树只有达到叶子结点才命中(B树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的性质:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统。
9.B* 树
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针,将结点的最低利用率从1/2提高到2/3。
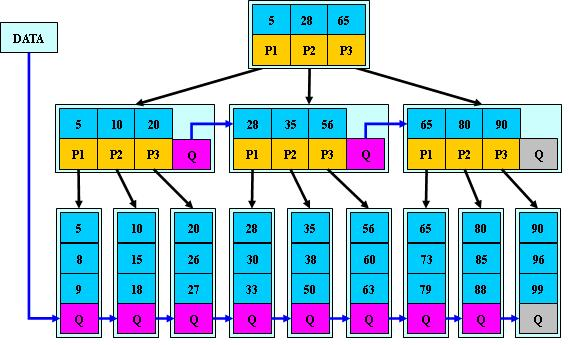
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高
10.Trie 树
Tire树称为字典树,又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。 它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。Tire树的三个基本性质:1) 根节点不包含字符,除根节点外每一个节点都只包含一个字符;2) 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;3) 每个节点的所有子节点包含的字符都不相同。 Tire树的应用:1) 串的快速检索 给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树, 然后读入文章进行比较,这种方法效率是比较高的。2) “串”排序 给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出。用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。 对这棵树进行先序遍历即可。3) 最长公共前缀 对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为求公共祖先的问题。
11.最优二叉树(哈夫曼树)
结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。 结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。 树的带权路径长度(Weighted Path Length of Tree:WPL):定义为树中全部叶子结点的带权路径长度之和 逆向构建一棵哈夫曼树: